Messdaten in VMware-Umgebungen analysieren (2)
Bei Performanceproblemen von ESXi-Hosts muss der Administrator in der Lage sein, die Leistungsindikatoren auszulesen und die gemessenen Werte zu verstehen. Dieser Beitrag stellt hierzu das Know-how bereit. Für die vier Kernressourcen CPU, RAM, Storage und Netz erläutern wir die wichtigsten Metriken. Wo sinnvoll, zeigen wir auch Schwellenwerte und mögliche Ursachen von Engpässen sowie Gegenmaßnahmen. Im zweiten Teil der Workshop-Serie geht es um das Arbeitsspeicher-Management beim ESXi-Host. Dabei erklären wir Begriffe wie Transparent Page Sharing, Ballooning und Memory Compression.

Das Speichermanagement des ESXi-Hosts erlaubt grundsätzlich das Überbuchen von RAM. Dies ist insbesondere unter der Annahme, dass VMs meist nicht den gesamten konfigurierten Speicher nutzen, durchaus legitim. Erkennt der ESXi-Host einen Speicherengpass, stehen ihm mehrere Mechanismen zur Verfügung, um Speicher einzusparen:
- Transparent Page Sharing
- Ballooning
- Memory Compression
- Host Swap Cache
- Host Level Swapping
Nähere Details zu den Mechanismen sowie Informationen dazu, wann die einzelnen Mechanismen greifen, sind sehr ausführlich hier beschrieben.
Transparent Page Sharing
Der Mechanismus "Transparent Page Sharing" (TPS) findet im Hintergrund statt. Er vergleicht im physischen RAM vorhandene Speicherseiten miteinander. Findet der Mechanismus identische Speicherseiten, behält er nur eine Kopie von ihr im physischen RAM bei, die anderen markiert er wieder als frei. Da nun mehrere VMs auf dieselbe Speicherseite Zugriff haben, werden diese schreibgeschützt (read only). Möchte eine VM auf eine gemeinsam genutzte Speicherseite schreibend zugreifen, erhält sie eine private Kopie (copy on write – COW).
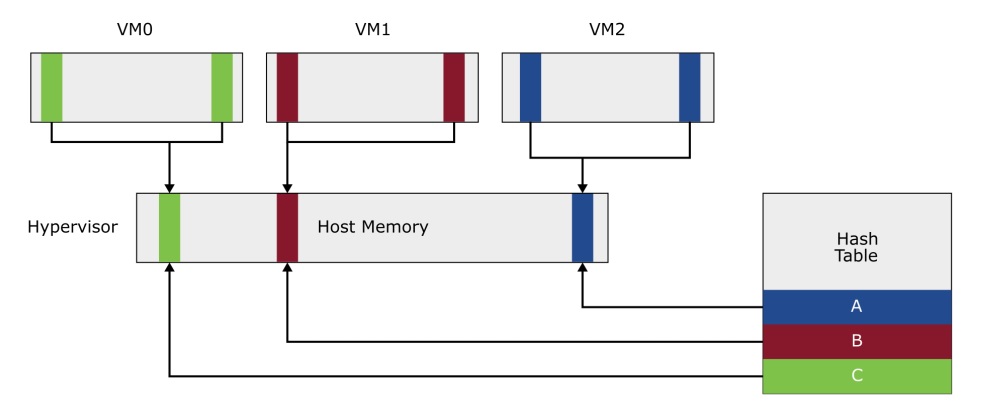
Das transparente hierbei ist, dass die VM keinerlei Kenntnis von diesem Vorgang hat. Allerdings verursacht das Erzeugen einer privaten Kopie einer Speicherseite eine minimale Verzögerung beim Schreibzugriff. Insgesamt lässt sich aber feststellen, dass TPS nahezu keinen negativen Einfluss auf die Performance hat. Mithilfe von zwei Metriken erkennen Sie, ob und in welchem Umfang TPS stattfindet (bei der Ansicht "memory"aus Bild 1 Feld N einblenden):
- SHRD: Speichermenge in MByte, die geteilt ist
- SHRDSVD: Durch TPS eingesparte Speichermenge in MByte
Ballooning
Dieser Mechanismus erfordert den in der VM installierten "Balloon Driver", der Bestandteil der VMware-Tools ist. Er ermöglicht es dem Hypervisor, einer laufenden VM sozusagen Speicher wegzunehmen. Der Gedanke hierbei ist relativ einfach: Beim ersten Zugriff einer VM auf eine Speicherseite alloziert der Hypervisor diese im physischen RAM. Wird die Speicherseite im Gastsystem wieder freigegeben, hat der Hypervisor hiervon keine Kenntnis. Lediglich im Gastsystem ist die Seite wieder als frei markiert. Fordert der Hypervisor nun über den Balloon Driver Speicher von der VM an, wird im Gastsystem bevorzugt ungenutzter Speicher alloziert und im Hypervisor freigegeben.
Damit ist Ballooning ein wichtiger Mechanismus, um Speicher von überdimensionierten VMs zurückzugewinnen. Der Einfluss auf die Performance hängt stark von der Charakteristik des Gastsystems und seiner Applikationen ab. Ist im Gastsystem ausreichend Speicher frei, ist der Performancenachteil nahe null. Datenbank-VMs beispielsweise, die den konfigurierten Speicher stark auslasten, können allerdings deutliche Performancenachteile aufweisen. Diese sollten Sie eventuell mit einer hohen Speichergarantie (Memory Reservation) versehen.
Die wichtigsten Performanceindikatoren sind in der Ansicht "memory" über das Feld J vorzufinden:
- MCTLSZ: Speichermenge in MByte, die per Ballooning entnommen wurde
- MCTLTGT: Das Ziel der zu entnehmenden Speichermenge
- MCTL?: Ist der Balloon Driver verfügbar (Yes/No)? Bei "No" sind eventuell keine VMware-Tools installiert.
"MCTL?" Sollte meistens auf "Yes" stehen. Eine Ausnahme sind zum Beispiel NSXT-Edge-Nodes, bei denen Ballooning absichtlich deaktiviert ist. "MCTLSZ" und "MCTLTGT" sollten "0" sein.
Memory Compression
Bei starkem Speicherengpass kann der Hypervisor Speicherseiten komprimieren, was immer noch effizienter ist, als sie per Host level swapping auszulagern. Die sogenannte Memory Compression findet allerdings erst bei starker Speichernot statt und sollte bei sinnvoller Dimensionierung der RAM-Ressourcen nicht auftreten. Die wichtigsten Messwerte erhalten Sie in der Ansicht "memory" über das Feld Q:
- CACHEUSD: Speichermenge in MByte, die komprimiert ist.
- ZIP/s und UNZIP/s: die Anzahl von (De)Komprimierungen pro Sekunde. Diese Messwerte sollten 0 betragen.
Host Level Swapping und Host Swap Cache
Ist der Hypervisor tatsächlich gezwungen, Speicherseiten auszulagern, leidet die Performance in der Regel deutlich. Speichernot, die zu Host Level Swapping führt, müssen Sie umgehend beheben, zum Beispiel durch die Migration von VMs auf geringer ausgelastete Hosts oder das Einschalten von DRS im vSphere-Cluster. Die folgenden Metriken sind hier relevant (in der Ansicht "memory" das Feld K einblenden):
- SWCUR: Speichermenge in MByte, die ausgelagert ist
- SWTGT: Das Ziel in MByte der auszulagernden Speichermenge.
- SWR/s und SWW/s: Swap-Lese- und Schreiboperationen pro Sekunde.
- SWPWT (CPU-Ansicht): Performanceverlust in Prozent durch Host Level Swapping. Alle Messwerte sollten im Normalbetrieb "0" betragen.
Zwar lässt sich durch Einsatz lokaler SSDs in den ESXi-Hosts und die Konfiguration eines Host-Caches für Swapping auf diesen SSDs der Performanceverlust reduzieren, aber es gibt fast keine Firmen, die diesen Mechanismus einsetzen. Findet dauerhaft Swapping statt, ist die Anschaffung von zusätzlichen Ressourcen der einzig sinnvolle Ausweg.
Verzögerungen als Performanceindikatoren
Die wichtigsten Performanceindikatoren bezüglich Storage sind die auftretenden Verzögerungen. Die hier angegeben Schwellenwerte dienen nur als Richtwerte, ein All-Flash-Storage-System sollte deutlich bessere Werte erzielen. Auch der gemessene Durchsatz ist wichtig. Eine VM, die nur wenige 100 KByte pro Sekunde sendet und empfängt, ist wahrscheinlich nicht durch die Storage-Performance beeinträchtigt.
Der Zugriff auf Massenspeicher aus einer VM heraus erfolgt über mehrere Schritte. Die Anfrage der VM muss zunächst den Hypervisor durchlaufen und dann in der Warteschlage zum Senden abgelegt werden. Füllt sich diese Warteschlage, verursacht dies Verzögerungen. Antworten vom Storage-System müssen erneut den Hypervisor durchlaufen. Ein von den CPUs her stark überlasteter ESXi-Host kann hier zusätzliche Verzögerungen verursachen.
Die Übertragung von Anfragen an beziehungsweise Antworten vom Storage-System erfolgt je nach verwendeter Technologie über das Netz (iSCSI, NFS, vSAN) oder bei Fibre Channel über einen Host Bus Adapter (HBA). Vom Senden der Anfrage bis zum Erhalt der zughörigen Antwort vergeht ebenfalls eine gewisse Zeit. Die gemessenen Werte sind immer im Zusammenhang mit dem Durchsatz zu betrachten. Ein plötzlicher, massiver Anstieg der Schreiblatenz bei gleichbleibendem Durchsatz könnte zum Beispiel auf einen deaktivierten oder defekten Cache des Storage-Systems hinweisen.
Storage-Metriken stehen unter drei verschiedenen Blickwinkeln zur Verfügung und lassen sich über die in Teil 1 im Bild gezeigten Optionen auswählen:
- Disk adapter (controller, HBA, Taste d)
- Disk device (LUN, Taste u)
- Disks der VMs (Taste v)
ln/jm/Torsten Mutayi
Im dritten Teil des Workshops geben wir einen Überblick zu den Gründen von Verzögerungen im Hypervisor und zeigen, wie Sie mit Paketverlusten beim Senden und Empfangen umgehen. Im ersten Teil haben wir erklärt, wie Sie Metriken mit esxtop analysieren und CPU-Schwellenwerte festlegen.


