
Cluster mit Raspberry Pi - Im Gleichklang (2)
Eine Handvoll Raspberry-Rechner lässt sich als Testplattform für Docker-Container verwenden, wie der erste Teil unseres Workshops gezeigt hat. Damit die kleinen Rechner zusammenarbeiten, setzen wir jetzt die Orchestrierungslösung Kubernetes ein.

In der letzten Folge unseres Workshops [1] haben wir auf einem Raspberry-Cluster die Raspbian-Distribution installiert und so konfiguriert, dass darauf die Container-Software Docker läuft. Nun soll es darum gehen, dass der Cluster auch als Cluster fungiert, also die einzelnen Raspberry-Maschinen sinnvoll zusammenarbeiten. Dabei soll kein klassisches Cluster-Tool wie Pacemaker verwendet werden, sondern eine Orchestrierungs-Lösung, die auf Container setzt.
Docker hat seit Version 1.12 den "Swarm-Mode" eingebaut, der vorher als Standalone-Software verfügbar war und Docker-Hosts mit der Fähigkeit zum Clustering ausstattet. Im Swarm-Mode wird einer der Nodes zu einem "Master", der die anderen Nodes steuert, auf denen die Container laufen. Da der Swarm-Mode schon in Docker integriert ist, übernimmt Docker automatisch viel vom Setup, das hinter den Kulissen ablaufen muss, etwa beim Aufbau eines virtuellen Netzwerks zwischen den Nodes.
Da die Firma hinter Docker aber auf der Haus-Konferenz Dockercon Ende letzten Jahres angekündigt hat, die von Google initiierte Orchestrierungssoftware Kubernetes zu integrieren, handelt es sich bei Swarm wohl um ein Auslaufmodell, auch wenn Docker bisher öffentlich beteuert, beide Lösungen parallel zu pflegen. Langfristig wäre das aber vermutlich wenig sinnvoll und zu aufwendig, sodass Kubernetes auf jeden Fall die zukunftsträchtigere Lösung ist, zumal auch beinahe alle großen Anbieter (etwa Microsoft, IBM, Red Hat, Google) darauf setzen und hinter Kubernetes mit der Cloud Native Computing Foundation (CNCF) ein großes Konsortium steht.
Die meiste Arbeit der Portierung auf die ARM-Plattform hat ein junger Programmierer namens Lucas Käldström geleistet. Neben seinen Beiträgen zum Code von Kubernetes und Kubeadm hat er auch einen Vorschlag dafür erarbeitet, wie ein Multi-Plattform-Cluster auf der Basis von Kubernetes aussehen könnte. Neben AMD64 und ARM32 unterstützt Kubernetes derzeit auch ARM64 und Power64.
Listing 1: setup-kubeadm.yml
--- - hosts: cluster remote_user: oliver become: true gather_facts: False tasks: - apt_key: url=https://packages.cloud.google.com/apt/doc/apt-key.gpg - apt_repository: repo: deb http://apt.kubernetes.io/ kubernetes-xenial main - apt: name: kubeadm update_cache: yes
Zur Installation von Kubernetes gibt es einige offizielle Tools, die sich in unterschiedlichen Entwicklungsstadien befinden und auch für verschiedene Plattformen gedacht sind. So ist ein Tool namens Kops dafür gedacht, Kubernetes auf einem der unterstützten Cloud-Services wie Amazon oder Google zum Laufen zu bringen. Kubespray (früher: Kargo) verwendet Ansible und ist für Bare Metal und Clouds konzipiert. Wir verwenden Kubeadm, das es ermöglicht (oder erfordert) die wenigen Schritte zur Installation eines Kubernetes-Clusters von Hand zu absolvieren. Im Übrigen ist hier, wie auch bei Kubernetes, noch alles im Fluss, und es entstehen immer wieder neue Ansätze wie beispielsweise das kürzlich vorgestellte Werkzeug Kubicorn.
Das Kubeadm-Tool lässt sich von einem bei Google gehosteten Repository herunterladen, in dem auch die für den Betrieb notwendigen Tools Kubelet und Kubectl vorhanden sind. Das Repository und der zugehörige GPG-Schlüssel sind im Ansible-Playbook in Listing 1 zu sehen. Hier ist nur das Paket "kubeadm" aufgeführt, die Pakete "kubectl" und "kubelet" werden automatisch als Abhängigkeiten installiert. Die Installation auf allen Nodes des Raspberry-Clusters startet dieser Aufruf:
$ ansible-playbook -i hosts -bK setup-kubeadm.yml
Wie Swarm basiert auch Kubernetes auf einem Master-Node-Modell. In unserem einfachen Fall soll es einen einzigen Master geben (node1), der die Verteilung von Containern auf den restlichen Nodes steuert. In einem Produktions-Setup würde man auch den Master mehrfach auslegen, wobei wegen der Randbedingungen des im Cluster verwendeten Raft-Algorithmus mindestens drei Master verwendet werden müssen.
Swap muss deaktiviert sein
Kubernetes ist dafür ausgelegt, auf einem System installiert zu werden, auf dem es keine aktive Swap-Partition/File gibt. Der Grund dafür ist, dass der Betrieb von Containern auf Servern mit Swap viele Dinge erschwert, etwa die Einhaltung von Memory Limits. Auch ist es wenig sinnvoll, wenn der Host einzelne Container oder Teile davon in den Swap-Bereich auslagert. Bestenfalls melden Tools wie Kubeadm bei der Installation, dass Swap aktiviert ist, schlimmstenfalls funktioniert irgendetwas einfach nicht richtig. Deshalb ist es das Beste, auf allen beteiligten Rechnern von der Kubernetes-Installation Swap einfach abzuschalten. Auf dem Raspberry sieht das etwas anders aus als auf den meisten anderen Linux-Distributionen. Wie gehabt erledigen wir das per Ansible gleich wieder auf allen Nodes:
$ ansible -i hosts cluster -bK -m shell -a 'systemctl stop dphys-swapfile && systemctl disable dphys-swapfile'
Um jetzt Kubernetes zu initialisieren, loggen Sie sich per SSH auf dem ersten Node ein. Sicherheitshalber können Sie überprüfen, ob "kubeadm", "kubelet" und "kubectl" installiert und ausführbar sind. Schließlich starten Sie die Initialisierung des Clusters mit:
$ sudo kubeadm init
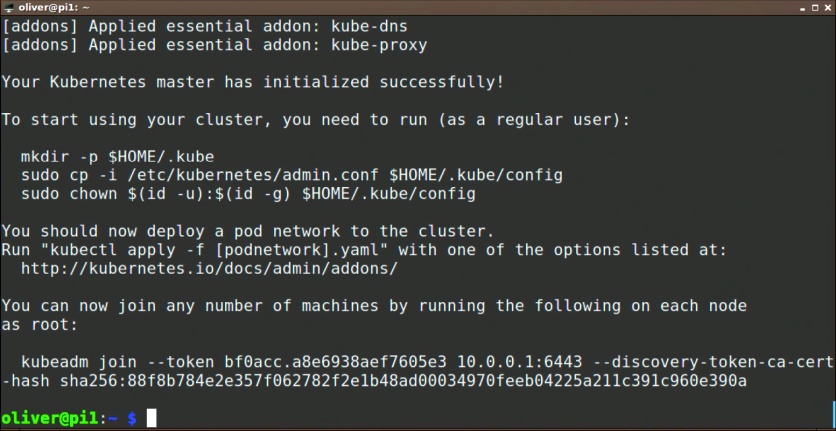
und das Join-Kommando für die Nodes aus.
Hat alles funktioniert, finden Sie am Ende der Ausgabe (Bild 1) einige Befehle, die Sie ausführen müssen, damit Sie beispielsweise den Kubernetes-Cluster als normaler User administrieren können. Damit wird die Cluster-Konfiguration in Ihr Home-Verzeichnis kopiert und für Sie lesbar gemacht. Anschließend können Sie den Cluster mit "kubectl", das seine Konfiguration aus dieser Datei bezieht, verwalten. So geben Sie mit kubectl get nodes die im Cluster vorhandenen Nodes aus:
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ kubectl get nodes
Unverzichtbar: Overlay-Netzwerk
Ebenfalls in der Ausgabe zu sehen ist der Befehl, den Sie auf den Worker-Nodes verwenden, um dem Kubernetes-Cluster beizutreten. Er enthält zur Authentifizierung ein Security-Token. Bevor Sie dies tun, müssen Sie erst ein Overlay-Netzwerk installieren. Zur Auswahl stehen Flannel und Weave Net, denn andere Optionen wie Calico, Canal und Romana sind nur für AMD64 verfügbar. Wer Flannel verwenden möchte, muss schon bei der Initialisierung des Clusters mit dem Parameter "--pod-network-cidr=10.244.0.0/16" das verwendete Netzwerk angeben. Ist der Cluster bereits initialisiert, lässt sich der Ausgangszustand wieder mit kubeadm reset erreichen. Wir verwenden in unserem Beispiel Weave Net, das keine Einschränkungen auferlegt. Installiert wird es folgendermaßen:
$ export kubever=$(kubectl version | base64 | tr -d '\n')
$ kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$kubever"
Jetzt können Sie sich auf den anderen Nodes einloggen und dort das ausgegebene Join-Kommando ausführen. Oder Sie verwenden auch dafür Ansible, wenn Sie für die Nodes eine eigene Host-Gruppe angelegt haben:
$ ansible -i hosts nodes -bKa "kubeadm join --token bf0acc.a8e6938aef7605e3 10.0.0.1:6443 --discovery-token-ca-cert-hash sha256:88f8b784e2e357f062782f2e1b48ad00034970feeb04225a211c391c960e390a"
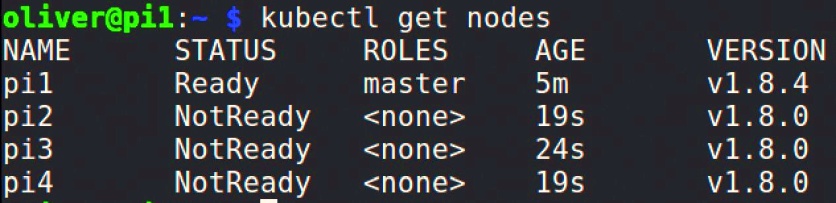
Führen Sie nun wieder kubectl get nodes aus, sehen Sie eine Ausgabe wie in Bild 2. Es dauert eventuell ein paar Minuten, bis alle Nodes "Ready" sind. Nun ist der Kubernetes-Cluster einsatzbereit.
Als Anwendungsbeispiel können Sie nun das Kubernetes-Dashboard installieren, ein webbasiertes grafisches Frontend. Die dafür nötige Konfigurationsdatei gibt es in einer speziellen Ausgabe für ARM, die Sie so herunterladen:
$ wget https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/recommended/kubernetes-dashboard-arm-head.yaml
Werfen Sie ruhig einen Blick in die Datei, sie ist nicht sehr kompliziert aufgebaut. Dann teilen Sie dem Kubernetes-Master mit einem Aufruf von "kubectl apply" mit, dass er diese "deklarative" Konfiguration umsetzen soll:
$ kubectl apply -f kubernetes-dashboard-arm-head.yaml
secret "kubernetes-dashboard-certs" created
serviceaccount "kubernetes-dashboard-head" created
role "kubernetes-dashboard-minimal-head" created
rolebinding "kubernetes-dashboard-minimal-head" created
deployment "kubernetes-dashboard-head" created
service "kubernetes-dashboard-head" created
Den jetzt erzeugten Service, der die Tür zur Kubernetes-Außenwelt darstellt, können Sie mit kubectl get services anzeigen, aber nur, wenn Sie mit "-n" den Namespace "kube-system" angeben oder sich mit "--all-namespaces" die Services aller Namespaces ausgeben lassen (Listing 2).
Listing 2: Services aller Kubernetes-Namespaces
kubectl get services –all-namespaces NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE default kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4h kube-system kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP 4h kube-system kubernetes-dashboard-head ClusterIP 10.104.70.226 <none> 443/TCP 2m
Nun müssen Sie noch den Kube-Proxy starten, und zwar aus Sicherheitsgründen auf einem Rechner, von dem aus Sie per Localhost auf ihn zugreifen können. Wenn Sie also etwa den Browser auf einem Laptop oder einer Workstation starten wollen, muss der Kube-Proxy auch darauf laufen. Das wiederum setzt voraus, dass Sie die Kubectl-Konfiguration vom Master auf diesen Rechner kopieren, zum Beispiel mit Secure Copy. Danach starten Sie dort den Proxy:
$ mkdir pi-cluster
$ cd pi-cluster
$ scp 10.0.0.1:.kube/config kubeconfig
$ kubectl --kubeconfig=kubeconfig proxy
Auf dem gleichen Rechner erreichen Sie das Dashboard nun unter der URL "http://localhost:8001/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard-head:/proxy/". Nur anfangen können Sie damit jetzt wenig, denn seit Version 1.7 haben die Entwickler die Rechte des Dashboard-Service-Accounts aus Sicherheitsgründen stark eingeschränkt. Die Wiki-Seite [2] beschreibt verschiedene Wege, entweder einzelne Rechte zu vergeben oder die alte Funktion mit vollen Admin-Rechten wiederherzustellen. Für Letzteres legen Sie auf dem Master die Datei "dashboard-admin.yml" (Listing 3) an und stellen mit dem Aufruf kubectl create -f dashboard-admin.yml das entsprechende Cluster-Role-Binding her.
Listing 3: dashboard-admin.yml
apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: kubernetes-dashboard-head labels: k8s-app: kubernetes-dashboard-head roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: cluster-admin subjects: - kind: ServiceAccount name: kubernetes-dashboard-head namespace: kube-system
Werden Sie beim Aufruf des Dashboards im Browser nach den Credentials gefragt, können Sie diesen Schritt einfach mit "SKIP" überspringen. Nun können Sie im Dashboard viele Eigenschaften des Kubernetes-Cluster konfigurieren und beispielsweise Pods und Deployments anlegen. Wechseln Sie im Menü links den Namespace auf "kube-system", können Sie beispielsweise die Pods sehen, die zu Kubernetes selbst gehören.
Fazit
Da die ARM-Architektur von Kubernetes unterstützt wird, ist es nicht schwer, sie auf einem Raspberry-Cluster zu installieren. Da aber noch nicht alle Feinheiten ausgereift sind und sich Kubernetes in kontinuierlicher Entwicklung befindet, gibt es noch ein paar Eigenheiten zu beachten, um beispielsweise das Dashboard zum Laufen zu bringen. Dann steht den eigenen Experimenten mit Kubernetes auf einem Raspberry-Cluster nichts mehr im Weg.
Aus dem IT-Administrator Magazin Ausgabe 01/2018: Softwareverteilung & Patchmanagement , Seite 55-57
Hier geht es zum ersten Teil von Cluster mit Raspberry Pi - Modellbau
Link-Codes
[1] Cluster mit Raspberry Pi, Teil 1, IT-Administrator 12/2017, S. 48: https://www.it-administrator.de/Cluster_Raspberry_Pi-1
[2] Kubernetes Dashboard Access control: https://github.com/kubernetes/dashboard/wiki/Access-control/


")