Moderner Storage im Zusammenspiel mit Containern
Zu Beginn kamen Container vor allem für Stateless-Anwendungen wie Webserver zum Einsatz. Da Container-Frameworks und Orchestrierungssysteme wie Kubernetes einen immer größeren Teil der Unternehmens-IT einnehmen, haben Firmen ihre Verwendung auf Datenbanken und andere Stateful-Anwendungen ausgeweitet. Organisationen haben eine Vielzahl von Optionen, wenn sie persistente Volumes für ihre Stateful-Anwendungen erstellen wollen – aber wie sind Einfachheit, Schnelligkeit und Wirtschaftlichkeit hier bestmöglich unter einen Hut zu bringen?

Die Storage-Branche arbeitet seit Anfang der 2010er Jahre daran, die Wirtschaftlichkeit von Flash-Speicher weiter zu verbessern. Vollständig Flash-basierte Plattformen sollen zum bevorzugten Speichermedium für alle Anwendungen werden – von Hochleistungsdatenbanken bis hin zu den größten Datenarchiven. Die kompromissbehafteten Hybridprodukte aus HDD und Flash werden hingegen immer mehr zum Auslaufmodell. Gefragt sind heute besonders leistungsfähige und skalierbare Datei- und Objektspeicherarchitekturen im Exabyte-Maßstab, die moderne Anwendungen wie Big-Data-Analytik und KI/ML unterstützen, ohne dass die Kosten aus dem Ruder laufen.
In den letzten fünf Jahren haben einige bedeutende neue Technologien den Siegeszug von Flash noch stärker begünstigt. Als zukunftsweisend gilt die Kombination von kosteneffizienten Hyperscale-Flash-Laufwerken und Storage Class Memory (SCM) mit zustandslosen, containerisierten Speicherdiensten. Diese sind über NVMe-over-Fabrics-Netzwerke (NVMe-oF) mit niedriger Latenz verbunden, um eine Scale-out-fähige, Disaggregated-Shared-Everything -Architektur (DASE) bereitzustellen.
Globale Algorithmen der nächsten Generation sollen dabei ein neues Niveau an Speichereffizienz, Ausfallsicherheit und Skalierbarkeit schaffen. Die Vision dahinter ist, das Ende der HDD-Ära in Rechenzentren zu beschleunigen und sich vom komplexen Storage-Tiering zu verabschieden, das jahrzehntelang Kompromisse forderte zwischen Preis und Leistung. Ziel ist es, das Rechenzentrum zu vereinfachen und alle modernen Anwendungen zu beschleunigen. Disaggregated Storage – oder disaggregierter Speicher – ist hierbei der jüngste Trend.
Disaggregierter Speicher und DASE-Architektur
Wie eine Disaggregated-Storage-Plattform aussehen kann, zeigt das folgende Beispiel: Sie basiert auf einem Scale-out-Architekturkonzept, das aus zwei Bausteinen besteht, die sich über eine gemeinsame NVMe-Fabric skalieren lassen. Die Speicherkapazität stellt das System mittels robuster, hochdichter NVMe-oF-Storage-Enclosures bereit. Die Logik des Systems basiert auf zustandslosen Docker-Containern, die jeweils in der Lage sind, sich mit allen Medien in den Storage-Arrays zu verbinden und diese zu verwalten. Da die Rechenelemente von den Medien in einer Data-Center-Scale-Fabric getrennt sind, lassen sie sich unabhängig voneinander skalieren, wodurch Kapazität und Leistung entkoppelt sind.
In der DASE-Architektur hat jeder Storage-Server im Cluster direkten Zugriff auf alle Speichermedien des Clusters mit PCI-Levels und geringer Latenz. Der Begriff "disaggregiert" beschreibt dabei, wie ein Storage-Cluster die Storage-Server, die Daten verwalten, von den Enclosures trennt, die die Speichermedien, sowohl Flash als auch Storage Class Memory, enthalten. Dies ermöglicht die Skalierung der Cluster-Rechenressourcen unabhängig von der Speicherkapazität über ein handelsübliches Netzwerk im Rechenzentrumsmaßstab.
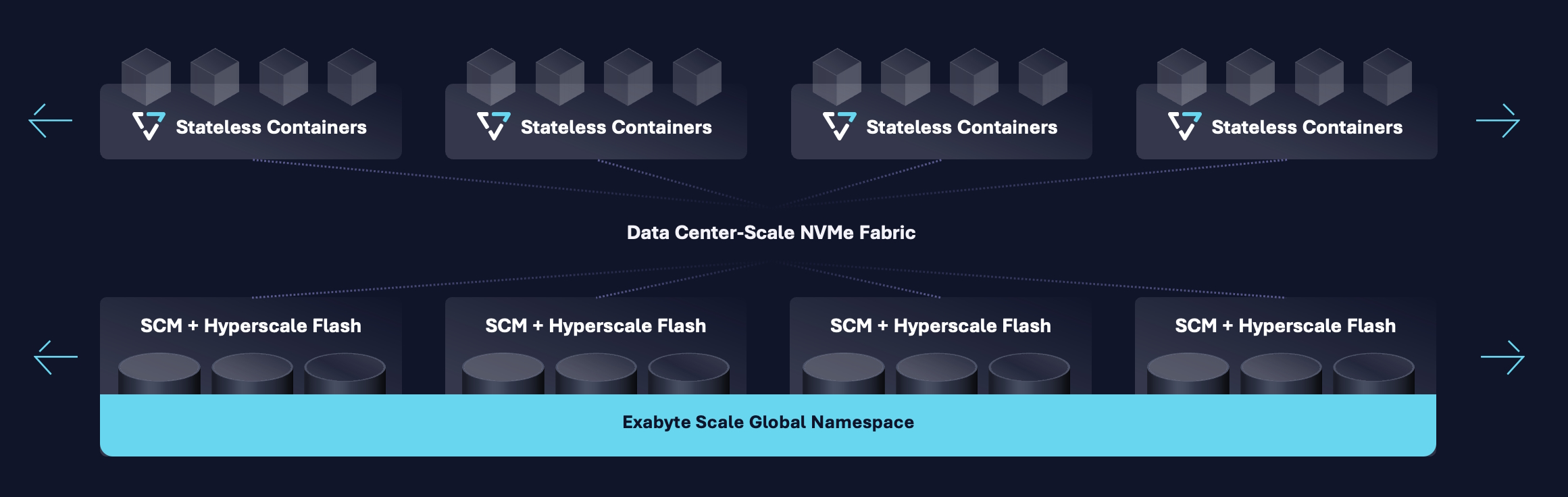
Das Shared-Everything-Konzept kombiniert dabei NVMe-oF mit einer Reihe von konsistenten Datenstrukturen, sodass alle Daten und Metadaten über alle Einheiten hinweg von allen Storage-Servern im Cluster global zugänglich sind. Diese Sichtweise ermöglicht es dem System, globale Algorithmen zu implementieren, die festlegen, wie der Cluster einen atomar konsistenten Namensraum aufbaut, eine globale Datenreduktion durchführt und die Daten schützt.
Separate Skalierung von Datenverarbeitung und Speicher
Disaggregierter Speicher ermöglicht Unternehmen die separate Skalierung von Datenverarbeitung und Speicher für hochleistungsfähige Workloads mit geringer Latenz. Die erhofften Vorteile sind Kosteneinsparungen, Flexibilität, Sicherheit und Datenschutz. Liegen Workloads mit unterschiedlichen Speicher-, Rechen-, IOPS-Anforderungen vor, ist disaggregierter Speicher ein effektiver Ansatz, um die Verwaltungskosten in Zaum zu halten. Hierbei handelt es sich um Infrastrukturbausteine, die es Unternehmen ermöglichen, über eine Netzwerkstruktur wie NVMe-oF auf logische Speicherpools zuzugreifen. Die daraus resultierende Möglichkeit, Rechenleistung und Speicher elastisch und unabhängig voneinander zu skalieren, gewährleistet eine hohe Verfügbarkeit von Storage-Ressourcen für anspruchsvolle moderne Anwendungsszenarien.
Disaggregierter Speicher ermöglicht eine dynamische Zuweisung von Ressourcen, je nach Anforderungen bestimmter Anwendungen sowie des möglichen I/O-Handlings, Durchsatzes und der Kapazität im Netzwerk. Unternehmen können dabei einer Anwendung so viele SSDs zuweisen wie nötig und die Kapazität später flexibel anpassen, auch reduzieren – ähnlich wie bei Cloudressourcen. Mit disaggregiertem Speicher können Organisationen somit eine dynamisch skalierbare Speicherarchitektur schaffen. So gelingt es, die sich ständig ändernden Ressourcenanforderungen bei verschiedenen Arbeitslasten bedienen zu können. Ziel ist es, einen schnellen Datenzugriff für alle Anwendungsbereiche, egal ob DevOps oder Analytik, zu ermöglichen.
Die Rolle der Container in Disaggregated-Storage-Architekturen
Mit NVMe-oF ist es seit einigen Jahren möglich, CPUs von Speichergeräten zu trennen, ohne während des Fernzugriffs auf SSDs die Leistung zu beeinträchtigen. Da Container immer häufiger für die Bereitstellung von Anwendungen zum Einsatz kommen, ermöglicht dieser Ansatz die einfache Bereitstellung und Skalierung von Datendiensten auf einer zusammensetzbaren Infrastruktur, wenn die Datenlokalisierung keine Rolle mehr spielt. Container sind die modernste und effizienteste Art, Anwendungen bereitzustellen. Aus diesem Grund laufen auch die Stateless-Server einer Disagreggated-Storage-Architektur in Server-Containern und stellen alle Speicherprotokoll- und Verwaltungsdienste in einem Cluster bereit. Jeder Stateless-Server kann direkt auf alle Speicherklassen und QLC-SSDs in allen Enclosures im Cluster zugreifen.
Kubernetes, als mittlerweile dominierende Orchestrierungs-Engine für Container, entwickelt und automatisiert die Bereitstellung und Verwaltung von Microservices-basierten Anwendungen in Container-Pods über ein Cluster von X86-Server-Nodes. Da die Benutzer immer komplexere und datenintensivere Anwendungen in Containern bereitstellen, hat die Container-Community Docker und Kubernetes um Persistent Volumes erweitert, um Speicher für diese Anwendungen bereitzustellen. Kubernetes unterstützt eine breite Palette von Datei-, Block- und Cloud-Speicheranbietern für Persistent Volumes unter Verwendung des quelloffenen CSI (Container Storage Interface). Neben Kubernetes können auch Disaggregated-Storage-Benutzer, die beispielsweise Apache Mesos und Cloud Foundry einsetzen, die Vorteile der Speicherautomatisierung über CSI nutzen. Ein CSI-Treiber bietet dabei eine Schnittstelle zwischen der Steuerebene des Kubernetes-Clusters und einem Storage-Cluster.
Der Einsatz eines CSI-Treibers bietet sich an als standardisierte Schnittstelle, die ein Kubernetes-Cluster nutzen kann, um Persistent Volumes in Form von Mounting-fähigen Ordnern für Pods von Containern bereitzustellen. Mittels Plug-ins, beispielsweise für OpenStack Manila, lässt sich eine engere Verbindung zwischen dem Storage-Cluster und der Open-Source-Cloud-Plattform OpenStack herstellen. Zusätzlich zu den Grundlagen der Veröffentlichung von Volumes für VMs, wie es CSI für Container vornimmt, automatisiert das Shared-File-Storage-Modul Manila auch die Erstellung von NFS-Exporten und die Einstellung der Zugriffsliste des Exports auf IP-Adressen. Dies erlaubt es Unternehmen-, den Prozess der Bereitstellung von Kubernetes- oder OpenShift-Clustern zu automatisieren, indem sie über OpenStack private Exporte für jeden Cluster erstellen, während sie über CSI die Volumes für Container-Pods bereitstellen.
Fazit
Das Disaggregated-Storage-Modell ist konzeptionell ähnlich wie Distributed Storage, aber vom Ansatz her neu gedacht. Bei Distributed Storage greifen Unternehmen nach Bedarf auf Cloudressourcen zu, um flexibler agieren zu können und die On-Premises-Ressourcen schlank zu halten. Der Zugriff auf Daten erfolgt über ein System zentraler Speicherknoten. Disaggregated Storage hingegen bietet sich für Unternehmen an, die skalierbaren Speicher mit orchestrierter Bereitstellung benötigen. Jeder Knoten hat dabei Kontakt zu allen über das Speichernetzwerk verfügbaren Ressourcen, was eine der Cloud ähnliche Benutzererfahrung in der eigenen Storage-Umgebung verspricht. Dieses Modell einer modernen Speicherarchitektur unterstützt die Effizienz von Containern und Microservices und wird Leistungs-, Flexibilitäts- und Kostenanforderungen optimal gerecht.
ln/Sven Breuner, Field CTO International at VAST Data


