Datenbanken im Überblick (2)
Datenbanken sind in der IT allgegenwärtig, doch nicht jede Datenbank eignet sich für jede Aufgabe. Gleichzeitig gibt es immer mehr Datenbankarten, aus denen Administratoren für neue Setups wählen können. Relationale Datenbanken, Zeitreihendatenbanken, NoSQL-Systeme, verteilte DBs – es ist nicht schwierig, dabei den Überblick zu verlieren. Wir verraten, welche DBs existieren und was Admins im Hinterkopf haben sollten. Im ersten Teil werfen wir einen Blick auf den Klassiker relationale Datenbanken. In der zweiten Folge geht es um verteilte Datenbanken und No-SQL-Systeme.

Verteilte Datenbanken für skalierbare Systeme
Relationale Datenbanken sind zuverlässig, performant und stabil – aber die allermeisten gängigen Implementierungen skalieren nicht zuverlässig in die Breite. Für die normale Website mit CMS im Hintergrund ist das zwar auch nicht nötig. Riesige Webshops jedoch, die abertausende Anfragen pro Sekunde abarbeiten müssen, werden eine einzelne Datenbank mit einiger Sicherheit an die Grenzen ihrer Leistungsfähigkeit bringen.
Ansätze zur Lösung des Problems gibt es einige, etwa Master-Slave-Szenarien, in denen zumindest etliche Backends für das Lesen von Daten zur Verfügung stehen. Früher waren die allermeisten Anwendungen im Unternehmensumfeld stark leselastig. Das ist heute zwar noch immer grundsätzlich so, jedoch verschiebt sich das Verhältnis langsam zugunsten von Schreibzugriffen. Nicht zuletzt daher hat es sich eingebürgert, echte Multi-Master-Setups zu bauen. Darunter versteht man verteilte Datenbanken, bei denen jeder einzelne Knoten sowohl den lesenden als auch den schreibenden Zugriff ermöglicht.
Nota bene: Verteilte Datenbanken können jede interne Struktur anwenden –neben verteilten RDBMS-Systemen sind auch verteilte Zeitreihendatenbanken denkbar. Aufgrund ihrer internen Struktur stellen verteilte RDBMS-Systeme aber technisch mit die höchste Hürde dar, die aus Sicht einer Datenbank denkbar ist. Denn zur Einhaltung der ACID-Regeln kommt hier neben den lokalen Herausforderungen die Aufgabe hinzu, die Transaktionen über die Grenzen einzelner Knoten und die Netzwerkgrenzen zwischen den Systemen hinweg sicher durchzuführen.
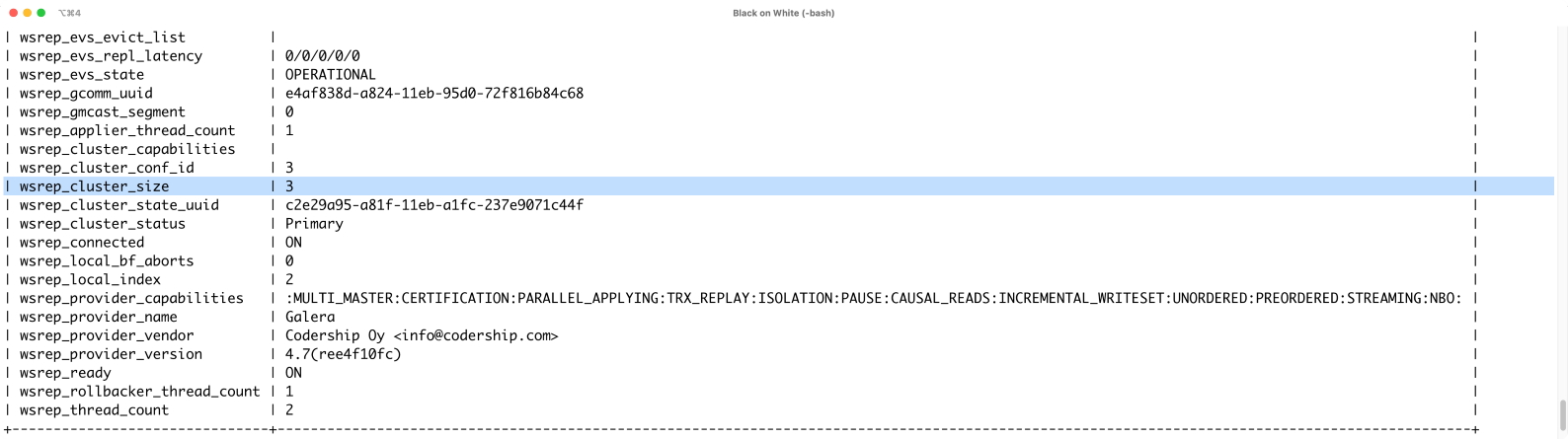
Verteilte Datenbanken kommen in der Regel nur dann zum Einsatz, wenn zuvor ein tatsächlicher Bedarf erhoben wurde. Denn der Betrieb einer solchen Lösung ist technisch nicht einfach und trivial. Wer einen realen Einsatzzweck hat, steht vor der Qual der Wahl: Für MariaDB sowie MySQL ist Galera [1] die verbreitetste Lösung. Bei PostgreSQL buhlen mehrere Ansätze um die Gunst der Nutzer, etwa Yugabyte oder CitusDB. Jeder dieser Ansätze hat allerdings eigene, spezifische Nachteile.
No-SQL-Datenbanken
RDBMS-Systeme nutzen als Abfragesprache (Query Language) einen Nachfolger der ebenfalls von E.F. Codd entwickelten Sprache "SEQUEL". SQL steht heute für "Structured Query Language" und beschreibt die Art und Weise, wie Anwender Daten in MySQL schreiben oder Daten aus der Datenbank auslesen. Praktisch jedes RDBMS-System der Gegenwart spricht einen SQL-Dialekt, wobei diese nicht unbedingt kompatibel miteinander sein müssen.
Basale Befehle etwa funktionieren auf MariaDB und PostgreSQL gleich oder zumindest ähnlich, bei komplexen Schritten sind aber oft völlig andere Kommandos nötig. Trotzdem: Weil RDBMS-Systeme lange den Markt komplett dominierten, wurde es irgendwann üblich, alle anderen Systeme unter dem Begriff "No-SQL-Datenbanken" zu subsummieren. Die Krux: Alleine anhand des Begriffes ist kein Rückschluss darauf möglich, um welche Art von Datenbank es sich handelt oder was deren spezifischen Fähigkeiten sind.
Eine Sonderform der No-SQL-Datenbanken stellt übrigens SQLite dar. Zwar kommt in SQLite eine Syntaxsprache zur Anwendung, die einen klassischen SQL-Dialekt darstellt. Die ganze Idee hinter SQLite besteht aber ja bekanntlich darin, keine echte Datenbank zu sein. SQLite-Datenbanken sind stattdessen in der Regel einzelne Textdateien auf der Festplatte, auf die der Zugriff durch ein spezielles Interface – etwa eine Bibliothek – erfolgt. Das ist zwar weder sonderlich performant noch skaliert es gut, gerade viele kleinere Programme sind so aber in der Lage, ihre eigenen Metadaten abzuspeichern. Und das ganz ohne Zwang für den Admin, eine separate Datenbank aufzusetzen.
Manchem werden viele Datenbanken eher unter ihrem Produktnamen begegnet sein als unter der Art, zu der das jeweilige Produkt gehört. MongoDB etwa erfreut sich seit einigen Jahren großer Beliebtheit und gehört zur Gruppe der No-SQL-Datenbanken. Es ist dokumentenorientiert, sodass Einträge etwa JSON- oder XML-Strukturen haben können. Mittlerweile steht MongoDB nicht mehr unter einer Open-Source-Lizenz, nach wie vor handelt es sich jedoch um die am weitesten verbreitete No-SQL-Datenbank überhaupt.
ln/Martin Loschwitz


